Inżynieria ochrony danych wg ENISA
Wstęp
Wraz z rozwojem technologii pojawiły się nowe techniki udostępniania, przetwarzania i przechowywania danych. Doprowadziło to do powstania nowych modeli przetwarzania danych (w tym danych osobowych), ale również wprowadziło nowe zagrożenia i wyzwania. Niektóre z nich to: brak kontroli i przejrzystości, możliwość ponownego, nieuprawnionego wykorzystania danych, wnioskowanie na podstawie danych i ponowna identyfikacja, a także profilowanie i zautomatyzowane podejmowanie decyzji. Z uwagi na wspomniane zagrożenia operacje przetwarzania muszą być dobrze przemyślane – z uwzględnieniem ważnej roli technologii jako elementu gwarancji bezpieczeństwa oraz środków technicznych i organizacyjnych, które muszą być odpowiednio wdrożone i skonfigurowane. Od strony technicznej wyzwanie polega głównie na przełożeniu określonych w RODO[1] zasad na konkretne wymagania i specyfikacje poprzez wybór, wdrożenie i skonfigurowanie odpowiednich środków technicznych i organizacyjnych, a także sposobu przetwarzania.
Takie podejście, nazywane inżynierią ochrony danych, może być postrzegane jako część ochrony danych już w fazie projektowania oraz jako domyślna ochrona danych. Ma na celu wspieranie wyboru, wdrażania i konfiguracji odpowiednich środków technicznych i organizacyjnych w celu spełnienia określonych zasad ochrony danych.
W omawianym opracowaniu ENISA, zatytułowanym „Inżynieria ochrony danych. Od teorii do praktyki”[2] i opublikowanym w lutym 2022 r., przyjrzano się szerzej inżynierii ochrony danych, aby wesprzeć praktyków i organizacje w praktycznym wdrażaniu technicznych aspektów ochrony danych w fazie projektowania i fazie domyślnej. Omówiono w nim m.in. anonimizację i pseudonimizację, maskowanie danych, bezpieczne przesyłanie i przechowywanie danych oraz przejrzystość i mechanizmy kontroli użytkownika nad danymi. Opracowanie powstało w kontekście zadań ENISA wynikających z rozporządzenia o bezpieczeństwie cybernetycznym (CSA)[3], polegających na wspieraniu państw członkowskich w konkretnych aspektach bezpieczeństwa cybernetycznego związanych z polityką i prawem UE w zakresie ochrony danych i prywatności. Prace te mają na celu zapewnienie podstaw do dalszej i bardziej szczegółowej analizy zidentyfikowanych kategorii technologii i technik przy jednoczesnym wykazaniu możliwości ich praktycznego zastosowania.
Inżynieria ochrony danych
Inżynieria prywatności jest dyscypliną wyłaniającą się z dziedziny projektowania systemów informatycznych, której celem jest zapewnienie narzędzi i technik umożliwiających stworzenie systemów zapewniających akceptowalny poziom prywatności oraz zgodność z wymaganiami funkcjonalnymi i niefunkcjonalnymi określonymi w polityce prywatności. Istnieją różne podejścia do zapewnienia prywatności w całym cyklu przetwarzania. ENISA np. w raporcie z 2015 r.dotyczącym koncepcji uwzględniania „Prywatności i ochrony danych w fazie projektowania”[4] przedstawiła osiem strategii uwzględnienia prywatności w fazie projektowania, zorientowanych zarówno na dane, jak i na proces przetwarzania. W innym podejściu[5] zaproponowano ramy składające się z sześciu celów. Do podstawowej trójki: „poufności”, „integralności” i „dostępności” dodano trzy cele dodatkowe: „brak powiązań”, „przejrzystość” oraz „możliwość interwencji”. Do rozwiązań z zakresu inżynierii ochrony danych należy zaliczyć również technologie ochrony prywatności znane pod nazwą PET (privacy enhancing technologies), będące „spójnym zestawem środków, który chroni prywatność poprzez eliminację lub ograniczenie danych osobowych lub poprzez zapobieganie niepotrzebnemu i/lub niepożądanemu przetwarzaniu danych osobowych, a wszystko to bez utraty funkcjonalności systemu informatycznego”. Strategie i cele ochrony danych osiągane w ramach inżynierii ochrony danych kładą nacisk na wbudowanie rozwiązań mających na celu spełnienie wymogów ochrony danych w operacjach przetwarzania. Środki te mają służyć ochronie przetwarzanych danych, których zastosowanie należy wykazać w szczególności podczas oceny skutków dla ochrony danych (art. 35 ust. 7 lit. d RODO).
Anonimizacja i pseudonimizacja
Anonimizacja, czyli proces polegający na usunięciu wszystkich informacji, które w jakikolwiek sposób umożliwiają identyfikację określonej osoby, której dane dotyczą, wymaga optymalizacji dwóch sprzecznych parametrów: użyteczności danych i ochrony przed ponowną identyfikacją. Znalezienie właściwego kompromisu w tym obszarze zależne jest od zastosowania i kontekstu, tj. zawartości i sposobu, w jaki dane są przedstawione, oraz celu, w jakim mają służyć. Zagadnienia te dość szeroko zostały omówione w opinii 05/2014 Grupy Roboczej Art. 29[6]. W niniejszym opracowaniu w celu wyjaśnienia przedstawiono model k-anonimowości wprowadzony w I dekadzie XXI wieku.
K-anonimowość opiera się na założeniu, że uogólnianie i mieszanie danych w zbiorach o podobnych atrybutach może ukryć informacje identyfikujące osoby, których dane dotyczą. Na przykład aby zanonimizować dane w zbiorze przedstawionym w tabeli A, można zastosować takie techniki jak usuwanie lub uogólnienie.
Tabela A
| Imię i nazwisko | Płeć | Kod pocztowy | Rok urodzenia | Diagnoza |
| Grzegorz S. | M | 75-016 | 1968 | Depresja |
| Marcin M. | M | 75-015 | 1970 | Cukrzyca |
| Maria J. | K | 69-100 | 1945 | Arytmia |
| Kasia M. | K | 69-100 | 1950 | Stwardnienie |
| Amelia F. | K | 75-016 | 1968 | Nic |
| Anna J. | K | 75-012 | 1964 | Reumatyzm |
| Zofia C. | K | 75-013 | 1964 | Anemia |
| Szymon P. | M | 75-019 | 1977 | Sarkoidoza |
| Michał J. | M | 75-018 | 1976 | Chłoniak |
W tym przypadku atrybut „Płeć” pozostaje niezmieniony, ponieważ jest istotny dla badań nad stanem choroby, natomiast atrybuty „Kod pocztowy” i „Rok urodzenia” zostały uogólnione. W przypadku kodu zachowano pierwsze dwie cyfry oznaczające rejon, rok zaś uogólniono do przedziału odpowiednio 10 lat. Po wykonaniu k-anonimizacji dla tego zbioru dla wartości k = 2 i quasi-identyfikatorów ze zbioru („Kod pocztowy”, „Rok urodzenia”, „Płeć”) tabela A zostaje przekształcona do tabeli B, w której dla każdej trójki wartości quasi-identyfikatorów istnieją co najmniej dwa wpisy.
Tabela B
| Kod pocztowy | Rok urodzenia | Płeć | Diagnoza |
| 75-*** | [1960–1970] | M | Depresja |
| Cukrzyca | |||
| 69-*** | [1940–1950] | K | Arytmia |
| Stwardnienie | |||
| 75-*** | [1960–1970] | K | Nic |
| Reumatyzm | |||
| Anemia | |||
| 75-*** | [1970–1980] | M | Sarkoidoza |
| Chłoniak |
K-anonimowość ma kilka ograniczeń. Na przykład kryterium k-anonimowości nie chroni przed atakami na jednorodność, w których wszystkie rekordy zgrupowane w klasie równoważności mają tę samą lub podobnie wrażliwą wartość. W celu rozwiązania tego problemu wprowadzono różne rozszerzenia modelu k-anonimowości, np. l-dywersyfikację (zróżnicowanie), która gwarantuje, że dla każdej wartości quasi-identyfikatora k danych będzie istniało co najmniej l reprezentatywnych wartości dla danych wrażliwych. Tabela B jest 2-anonimowa i 2-zróżnicowana, ponieważ w grupie osób o tym samym quasi-identyfikatorze zawsze występują co najmniej dwa różne schorzenia. Gdyby jednak Szymon P. miał chłoniaka zamiast sarkoidozy, tabela 2 nadal byłaby 2-anonimowa, ale nie byłaby już 2-zróżnicowana. W tym przypadku można by wywnioskować, że Michał J., który należy do grupy: 75, [1970–1980], M, ma chłoniaka, podczas gdy wcześniej takie przewidywanie było możliwe tylko z prawdopodobieństwem 50%. Kolejną słabością k-anonimowości jest to, że się nie składa, tzn. kilka k-anonimowych zbiorów danych dotyczących tych samych osób może być łączonych w celu ich ponownego zidentyfikowania. Dlatego bardzo trudno jest udzielić a priori gwarancji na ryzyko ponownej identyfikacji, które może zależeć od wiedzy przeciwnika.
Prywatność różnicowa to metoda anonimizacji, która umożliwia np. dostawcom danych udostępnianie prywatnych informacji w bezpieczny sposób[7], tj. bez ujawniania danych identyfikacyjnych. W metodzie tej, aby chronić prywatność, do rzeczywistych danych identyfikacyjnych dodaje się szum, co ma niewielki wpływ – lub nie ma go w ogóle – na ich użyteczność. Oznacza to, że na wyniki statystyczne ze zbioru danych nie powinien mieć wpływu wkład jednostki, ponieważ dane reprezentują cechy całej populacji. Niech D i D’ reprezentują dwa różne sąsiednie zestawy danych, różniące się tylko jednym zestawem danych. Prywatność różnicowa oznacza, że aby zabezpieczyć atrybuty prywatne w danym zbiorze danych przez dodanie szumu 𝜖, nie możemy przewidzieć, czy dany wpis istnieje w bazie danych, czy nie.
Jaki model anonimizacji zastosować? W opracowaniu podkreśla się, że anonimizacja danych to złożony proces, który powinien być przeprowadzany w każdym przypadku indywidualnie. Możliwe rozwiązania zależą od wielu parametrów, które różnią się w zależności od zastosowania, takich jak typ danych (dane czasowe, sekwencyjne, tabelaryczne itp.), wrażliwość danych czy też dopuszczalne poziomy ryzyka i obniżenia wydajności. Każda procedura anonimizacji powinna być połączona z analizą ryzyka i korzyści, w której określa się dopuszczalne poziomy ryzyka i wydajności. Taka analiza ryzyka będzie dla administratora danych wskazówką przy wyborze modelu, algorytmu i parametrów do zastosowania. Przyjęte rozwiązanie w zakresie anonimizacji powinno również zależeć od kontekstu, np. od tego, w jaki sposób anonimizowany zbiór danych będzie rozpowszechniany. Model „uwolnij i zapomnij”, w którym zanonimizowane dane są publicznie udostępniane bez kontroli, wymaga silniejszej ochrony niż model „Enclave”, w którym anonimowe dane są przechowywane przez administratora danych, a zapytania mogą być wykonywane tylko przez wykwalifikowanych badaczy. Podejścia k-anonimowości i prywatności różnicowej są czasami postrzegane jako konkurujące ze sobą, a jedno z nich może być stosowane zamiast drugiego. Jednak podejścia te, jak wykazali Clifton i Tassa[8], uzupełniają się i są dostosowane do różnych zastosowań.
Maskowanie danych
Maskowanie to szeroki termin odnoszący się do funkcji, które po zastosowaniu do danych ukrywają ich prawdziwą wartość. Najbardziej znanymi przykładami są szyfrowanie i haszowanie. Zalicza się do nich także takie technologie, jak: szyfrowanie homomorficzne, koncepcje bezpiecznych obliczeń wielostronnych, zaufane środowisko wykonawcze, wyszukiwanie informacji prywatnych czy koncepcje danych syntetycznych. Główną użytecznością maskowania w odniesieniu do zasad ochrony danych jest integralność i poufność (bezpieczeństwo), a w zależności od techniki lub kontekstu przetwarzania może również obejmować rozliczalność i ograniczenie celu.
Szyfrowanie homomorficzne – to technologia, która umożliwia wykonywanie obliczeń na zaszyfrowanych danych bez konieczności ich wcześniejszego odszyfrowania. Typowym przypadkiem użycia szyfrowania homomorficznego jest sytuacja, gdy osoba, której dane dotyczą, chce zlecić na zewnątrz przetwarzanie swoich danych osobowych bez ich ujawniania w postaci zwykłego tekstu. Takie funkcjonalności bardzo dobrze się sprawdzają, gdy przetwarzanie jest wykonywane przez stronę trzecią, np. dostawcę usług w chmurze.
Istnieją dwa rodzaje szyfrowania homomorficznego: częściowo i w pełni homomorficzne[9]. Szyfrowanie częściowo homomorficzne (partially homomorphic encryption, PHE) polega na tym, że na tekście szyfrującym można wykonać tylko jedną operację, np. dodawanie lub mnożenie. Z kolei szyfrowanie w pełni homomorficzne (fully homomorphic encryption, FHE) może obsługiwać operacje wielomianowe (obecnie dodawanie i mnożenie), co pozwala na wykonywanie większej liczby obliczeń na zaszyfrowanych danych.
Bezpieczne obliczenia wielostronne (secure multiparty computation, SMPC) – to protokół obliczeń między zbiorem stron polegający na rozdzieleniu obliczeń między te strony, przy czym żadna strona nie może zobaczyć danych innych stron. Do ważnych odmian SMPC należą aukcje[10], w których uczestnicy mogą składać oferty na aukcję bez ujawniania swoich ofert. Ta ostatnia została już wdrożona w Danii, gdzie duńscy rolnicy ustalają między sobą ceny buraków cukrowych bez potrzeby korzystania z centralnego aukcjonera.
Najbardziej prominentnym przykładem SMPC jest technologia blockchain, w której grupa stron, zwanych „górnikami”, musi określić i uzgodnić następny blok, który ma zostać dołączony do księgi głównej blockchain. W zależności od wybranego protokołu SMPC może wspierać cele związane z ochroną poufności (ponieważ dane wejściowe innych stron nie są ujawniane) i integralność (ponieważ zarówno wewnętrzni, jak i zewnętrzni uczestnicy nie mogą łatwo zmienić danych wyjściowych protokołu). Biorąc pod uwagę, że protokół wielostronnych obliczeń musi być znany każdej ze stron, rozwiązanie takie sprzyja przejrzystości co do rodzaju przetwarzania danych wejściowych. Wadą takiego rozwiązania jest brak możliwości usunięcia danych z bloku, który zostanie uzgodniony, co jest istotne w przypadku, gdyby znalazły się tam dane osobowe.
Zaufane środowisko przetwarzania (trusted execution environment, TEE) – to odporne na manipulacje, złośliwe oprogramowanie oraz nieautoryzowany dostęp środowisko przetwarzania danych na urządzeniu przetwarzającym dane. Gwarantuje ono autentyczność wykonywanego kodu, integralność stanów uruchomionego systemu (np. rejestrów procesora, pamięci i wejścia/wyjścia) oraz poufność kodu, danych i stanów uruchomieniowych. TEE jest odporny na ataki programowe, a także na fizyczne ataki na pamięć główną systemu. W przeciwieństwie do odpowiednich koprocesorów sprzętowych TEE jest w stanie łatwo zarządzać swoją zawartością poprzez instalację lub aktualizację kodu i danych. Układy TEE są powszechnie stosowane w różnych urządzeniach, takich jak smartfony, tablety i urządzenia IoT. Układy zawierające TEE mogą spełniać kluczowe funkcje, takie jak bezpieczna agregacja lub szyfrowanie w celu ograniczenia dostępu serwera do surowych danych lub klucza szyfrującego. Może to zapewnić weryfikowalność obliczeń i zwiększyć zaufanie.
Prywatność w wyszukiwaniu informacji (private information retrieval, PIR) – to technologia kryptograficzna umożliwiająca użytkownikowi odzyskanie informacji z bazy danych bez ujawniania osobie przechowującej dane (np. właścicielowi lub administratorowi bazy danych), które z nich były przedmiotem zapytania[11]. Może być ona stosowana przez administratorów danych jako technika minimalizacji danych. W tradycyjnym modelu udostępniania danych, gdy klient uzyskuje dostęp do bazy danych, administrator danych wie, do którego wpisu uzyskano dostęp. Z czasem administrator danych będzie w stanie określić, które wpisy w bazie danych są interesujące dla poszczególnych klientów. Aby ukryć przed administratorem informacje, do którego z n-elementów bazy użytkownik uzyskał dostęp, można wprowadzić schemat, w którym użytkownik przy każdym zapytaniu o np. k-element bazy danych pobiera wszystkie n-elementy bazy danych, co jest niekorzystne pod względem komunikacji między użytkownikiem i serwerem. Technologia PIR uniemożliwia administratorowi danych uzyskanie informacji, do których wpisów poszczególni użytkownicy uzyskali dostęp, przy ograniczonym transferze danych między serwerem i użytkownikiem[12].
Dane syntetyczne – to nowy obszar przetwarzania danych, w którym dane są opracowywane w taki sposób, że przypominają dane rzeczywiste (zarówno osobowe, jak i nieosobowe), ale w rzeczywistości nie odnoszą się one do żadnej konkretnej zidentyfikowanej lub możliwej do zidentyfikowania osoby fizycznej ani do rzeczywistej miary obserwowalnego parametru w przypadku danych nieosobowych.
Istnieje wiele metod generowania danych syntetycznych. Najprostszym rozwiązaniem jest losowanie próbek ze znanego rozkładu. W metodzie tej nie przetwarza się żadnych oryginalnych (i osobistych) danych, a ponowna identyfikacja jest mało prawdopodobna, głównie ze względu na losowość. Bardziej złożone opcje polegają na mieszaniu danych prawdziwych i fałszywych (te ostatnie są nadal próbkowane ze znanych rozkładów wielowymiarowych, uwarunkowanych rzeczywistymi obserwowanymi danymi). W przypadku mieszania niektóre ujawnienie danych osobowych i ponowna identyfikacja są możliwe ze względu na obecność prawdziwych wartości w zbiorze danych. Praktyczne generowanie danych syntetycznych opiera się zarówno na wykorzystaniu klasycznych procedur generowania liczb losowych, jak i – w coraz większym stopniu – na zastosowaniu sztucznej inteligencji i narzędzi uczenia maszynowego.
Dostęp do danych, przekazywanie i przechowywanie
Z punktu widzenia inżynierii ochrony danych kanały komunikacyjne powinny wykraczać poza bezpieczeństwo jako ich podstawową funkcjonalność. Powinny one zawierać dodatkowe cechy zwiększające prywatność, takie jak kontrola dostępu np. w zakresie tego, kto może mieć dostęp do treści komunikatu (w tym dostawcy, lokalizacja i dostęp do kluczy szyfrujących, lokalizacja i typ dostawcy, ujawnione informacje o użytkowniku itp.).
Bezpieczne kanały komunikacyjne – to środki służące zabezpieczeniu poufności przekazywanych treści. Do podstawowych technologii, które wykorzystywane są w tych celach, należy szyfrowanie end-to-end oraz proxy & onion routing.
Szyfrowanie end-to-end – to metoda szyfrowania danych i utrzymywania ich zaszyfrowanych przez cały czas między dwiema komunikującymi się stronami lub ich większą liczbą. Różni się ona od szyfrowania łącza lub szyfrowania w tranzycie tym, że w tych ostatnich przypadkach może być dostęp do treści przez serwer, w zależności od tego, gdzie odbywa się szyfrowanie lub gdzie przechowywane są klucze szyfrujące. Z kolei w typowym szyfrowaniu end-to-end klucze szyfrujące są przechowywane na urządzeniach użytkowników końcowych, a serwer ma informacje tylko o metadanych komunikacji, jego uczestnikach oraz dacie i czasie.
Proxy i cebulowy routing (proxy & onion routing) – to technologia, która zapewnia dodatkowo ochronę metadanych (tj. danych, które opisują inne dane i zawierają informacje o tym, kto, co, gdzie, kiedy itp.), które zgodnie z oświadczeniem EIOD[13] w sprawie zmiany dyrektywy o e-prywatności i wniosku dotyczącego rozporządzenia o e-prywatności „mogą pozwolić na bardzo precyzyjne wnioski dotyczące życia prywatnego ludzi, co wiąże się z wysokim ryzykiem dla ich praw i wolności”. W technologii tej ruch użytkowników jest kierowany przez szereg serwerów przekaźnikowych, z których każdy otrzymuje warstwowo zaszyfrowane dane, nie znając ani pierwotnego nadawcy, ani ostatecznego odbiorcy. Informacje te są dostępne tylko dla węzła wejściowego i wyjściowego.
Bezpieczne przechowywanie danych – to metody przechowywania danych, które zapewniają ochronę ich poufności w stanie spoczynku oraz informowanie administratora w przypadku ich naruszenia. Główną techniką stosowaną w tym celu jest kryptografia. W zależności od ograniczeń administratorów danych może być ona stosowana na trzech różnych poziomach: (i) na poziomie pamięci masowej, (ii) na poziomie bazy danych oraz (iii) szyfrowanie na poziomie aplikacji, co pokazano na rysunku poniżej.
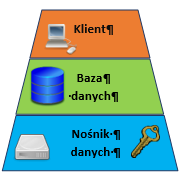
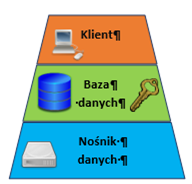
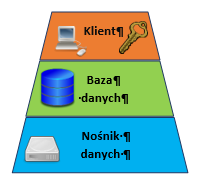
Jeśli chodzi natomiast o mechanizm powiadamiania administratora o naruszeniach lub próbach naruszenia danych, jednym z często stosowanych rozwiązań w inżynierii ochrony danych są tzw. kanarki. Są to dodatkowo umieszczone w bazie danych fałszywe pozycje, które nie powinny być przez nikogo używane. Powinny być one trudne do odróżnienia od innych, poprawnych wartości w bazie. Dostęp do tych wartości jest w szczególny sposób monitorowany, aby wykryć ewentualne naruszenia i powiadomić o tym administratora.
Kontrola dostępu, autoryzacja i uwierzytelnianie – to środki ochrony danych mające na celu zapobieganie nieautoryzowanym i/lub niepożądanym działaniom (takim jak nieautoryzowane przeglądanie, modyfikowanie lub kopiowanie) poprzez wdrożenie kontroli i ograniczeń dotyczących tego, co mogą robić użytkownicy, do jakich zasobów mają dostęp i jakie funkcje mogą wykonywać na danych. Uwierzytelnianie potwierdza tożsamość użytkownika żądającego dostępu do danych, a autoryzacja określa, jakie działania może podjąć uwierzytelniony użytkownik. W zależności od kontekstu i potrzeb pewne mechanizmy kontroli dostępu wydają się bardziej odpowiednie niż inne. Na przykład w scenariuszu, w którym przetwarzanie danych osobowych klientów dla celów marketingowych odbywa się za pośrednictwem dostawcy usług przechowywania danych w chmurze online, dyskrecjonalna (nazywana również uznaniową) kontrola dostępu (DAC) może być właściwym rozwiązaniem. Dzięki DAC pracownik może określić, jakie dane dla każdego zewnętrznego w stosunku do organizacji użytkownika i jakie działania są dozwolone. DAC zapewnia użytkownikom zaawansowaną elastyczność w zakresie ustawiania pożądanego zakresu kontroli dostępu. Z kolei w innym scenariuszu, np. w szpitalnym systemie informatycznym, w którym każdy uczestnik (lekarz, pielęgniarka, personel administracyjny) jest przypisany do różnych ról z różnymi uprawnieniami (np. lekarz może uzyskać dostęp do danych medycznych pacjentów), bardziej odpowiednia wydaje się kontrola dostępu oparta na rolach (RBAC).
Bezpieczne poświadczenie uwierzytelnienia – to technologie umożliwiające uwierzytelnienie podmiotów bez ujawniania ich tożsamości poprzez selektywne uwierzytelnianie różnych atrybutów bez ujawniania dodatkowych informacji, które są zwykle używane i mogą obejmować dane osobowe. Należą do nich technologia oparta na atrybutach (privacy-enhancing attribute-based credentials, PABC)[1] oraz dowody zerowej wiedzy (zero knowledge proof). Ta ostatnia technologia, wykorzystująca metody kryptograficzne, jest często stosowana do egzekwowania zasad poufności i zasad minimalizacji danych zawartych w RODO. Umożliwia ona użytkownikowi (osobie, której dane dotyczą) udowodnienie serwerowi (administratorowi danych), że zna tajną informację, nie ujawniając nic na temat tej tajemnicy. Kilka protokołów tej technologii zostało zaproponowanych w normie ISO/IEC 9798-515. Najbardziej znanym przykładem tej technologii jest uwierzytelnianie się użytkownika na serwerze – aby się uwierzytelnić, użytkownik musi podać identyfikator i hasło, które następnie jest porównywane z hasłem przechowywanym na serwerze. Przeciwnik, który chce podszyć się pod użytkownika, może wykraść hasło albo od niego, albo od serwera. W schemacie uwierzytelniania opartym na dowodach wiedzy zerowej ryzyko to jest ograniczone tylko do użytkownika, ponieważ serwer nie zna sekretu użytego przez użytkownika do uwierzytelnienia.
Przejrzystość, możliwość interwencji i kontrola użytkownika
Mając na uwadze potrzebę zapewnienia osobom, których dane są przetwarzane, ich praw przez administratora danych, kluczowym elementem każdej koncepcji ochrony danych jest umożliwienie osobom samodzielnego korzystania z praw do ochrony danych. Obejmuje to zarówno dostęp osoby do danych przetwarzanych na jej temat, celu i sposobu przetwarzania (przejrzystość), jak i możliwość wpływania na przetwarzanie jej danych osobowych przez administratora lub podmiot przetwarzający (możliwość interwencji). W związku z tym w środowisku badaczy prywatności pojawiło się wiele rozwiązań inżynierskich, które mogą pomóc we wdrożeniu tych praw i skorelowanych z nimi usług u administratora lub podmiotu przetwarzającego. Rozwiązania te zostały przedstawione poniżej.
Polityki prywatności oraz ikony prywatności – rozwiązania, które zapewniają łatwo dostępną i przejrzystą dla użytkowników informację o celach i zakresie przetwarzania ich danych. W opracowaniu podkreśla się, że dostarczanie osobie dokładnych informacji o przetwarzaniu jej danych nie jest łatwym zadaniem, ponieważ z jednej strony konieczne może być uproszczenie, tak by przeciętna osoba mogła zrozumieć te informacje, a z drugiej strony takie uproszczenie nie może prowadzić do nieporozumień. Dla informacji w języku naturalnym zaproponowano kilka metryk służących do pomiaru złożoności i zrozumiałości informacji. Takie metryki mogą być wykorzystywane przez administratorów do sprawdzania zrozumiałości ich polityki prywatności, nawet jeśli organy ochrony danych nie zaleciły jeszcze stosowania określonej metryki. W odniesieniu np. do dzieci Biuro Komisarza ds. Informacji w Wielkiej Brytanii opublikowało kodeks praktyk dla usług internetowych[2]. Przedstawiono w nim 15 zasad, które powinny być przestrzegane przy projektowaniu usług internetowych. W opracowaniu podkreślono możliwość stosowania ikon dla oznaczenia prywatności oraz mechanizmów umożliwiających zapisanie polityk ochrony danych w formacie maszynowym.
Sygnały o preferencjach prywatności – to rozwiązania, w których użytkownik w świecie online lub offline sam może wyrażać żądania lub życzenia dotyczące sposobu przetwarzania jego danych osobowych poprzez przekazywanie administratorowi znormalizowanych, nadających się do odczytu maszynowego preferencji prywatności od strony użytkownika. Pierwszym przykładem takiego podejścia, które ostatecznie się nie przyjęło, jest specyfikacja „Platformy Preferencji Prywatności” (P3P), która pozwalała na wyrażenie polityki prywatności po stronie serwera oraz uzupełniającej ją specyfikacji po stronie użytkownika. Innym przykładem jest standard „Do not track” (DNT), zgodnie z którym użytkownicy mogą wyrazić za pomocą pola nagłówka HTTP, czy chcą być śledzeni. „DNT = 1” oznacza, że „ten użytkownik woli nie być śledzony przy tym żądaniu”, podczas gdy „DNT = 0” oznacza, że „ten użytkownik zezwala na śledzenie tego żądania”. Trzecią możliwością jest niewysyłanie nagłówka DNT, jeżeli użytkownik nie włączył tej funkcji. Niedoskonałością standardu DNT jest brak przepisów prawnych w tym zakresie. Do jeszcze innych rozwiązań należy standard „Globalna kontrola prywatności” (GPC), który umożliwia użytkownikom wysyłanie do administratora sygnału „do-not-sell-or-share” („nie sprzedawać i nie udostępniać”), co oznacza, że użytkownik żąda, aby jego dane nie były sprzedawane ani udostępniane żadnej stronie innej niż ta, z którą użytkownik zamierza wejść w interakcję, z wyjątkiem przypadków dozwolonych przez prawo. Standard jest regulowany w obowiązującej od połowy 2021 r. ustawie California Consumer Privacy Act (CCPA). Użytkownicy, którzy chcą wysłać sygnał „nie sprzedawaj i nie udostępniaj”, mogą skorzystać z jednej z obsługiwanych przeglądarek lub rozszerzeń. Zgodnie z europejskim systemem ochrony danych usługodawcy nie są obecnie zmuszani do wdrażania konkretnych protokołów, które interpretują sygnały użytkowników dotyczące ich preferencji w zakresie prywatności.
Pulpity nawigacyjne dotyczące prywatności (privacy dashboards) – to mechanizmy zwiększające transparentność oraz zapewniające możliwość wglądu w dane i interwencji osobom, których dane dotyczą. Mechanizmy takie mają zastosowanie w usługach sektora publicznego. W Polsce przykładem takiego rozwiązania jest m.in. system Ministerstwa Zdrowia, w którym za pośrednictwem aplikacji Internetowe Konto Pacjenta użytkownik ma wgląd w dane dotyczące jego leczenia, co daje mu możliwość weryfikacji i interwencji, jeśli dane te nie są właściwe, np. gdy wizytę prywatną, opłaconą przez pacjenta, wpisano jako refundowaną przez NFZ.
Systemy zarządzania zgodami (consent management systems) – to rozwiązania inżynierii programowania, które automatyzują zbieranie i gromadzenie zgody na określone operacje przetwarzania. Zautomatyzowanie tego procesu umożliwia odciążenie tymi czynnościami zasobów ludzkich i skupienie się na innych zadaniach.
Wykonywanie praw dostępu do danych – to obowiązek administratora danych, którego realizacja dla dużych podmiotów może być bardzo poważnym wyzwaniem. Aby sprostać temu wyzwaniu, wiele nowoczesnych firm wdraża infrastrukturę techniczną i usługi umożliwiające automatyzację przetwarzania wniosków o taki dostęp, co najmniej w zakresie zbierania informacji o danej osobie. Czynność ta stanowi istotne wyzwanie szczególnie w przypadkach, kiedy w przetwarzaniu uczestniczy wielu podwykonawców. Rozwiązaniem może być również zapewnienie dostępu do danych poprzez np. pulpity nawigacyjne dotyczące prywatności, o których mowa wyżej.
[1] J. Camenisch, A. Lehmann, G. Neven i in., Privacy-Preserving Auditing for Attribute-Based Credentials, European Symposium on Research in Computer Security, 2014.
[2] Information Commissioner’s Office (ICO), Age appropriate design: a code of practice for online services, https://ico.org.uk/for-organisations/guide-to-data-protection/ico-codes-of-practice/age-appropriate-design-a-code-of-practice-for-online-services/information-commissioner-s-foreword/ (dostęp: 16.03.2022).
[1] Rozporządzenie Parlamentu Europejskiego i Rady (UE) 2016/679 z dnia 27 kwietnia 2016 r. w sprawie ochrony osób fizycznych w związku z przetwarzaniem danych osobowych i w sprawie swobodnego przepływu takich danych oraz uchylenia dyrektywy 95/46/WE (ogólne rozporządzenie o ochronie danych).
[2] European Union Agency for Cybersecurity (ENISA), Data Protection Engineering. From Theory to Practice, 2022, https://www.enisa.europa.eu/publications/data-protection-engineering (dostęp: 16.03.2022).
[3] Rozporządzenie Parlamentu Europejskiego i Rady (UE) 2019/881 z dnia 17 kwietnia 2019 r. w sprawie ENISA (Agencji Unii Europejskiej ds. Cyberbezpieczeństwa) oraz certyfikacji cyberbezpieczeństwa w zakresie technologii informacyjno-komunikacyjnych oraz uchylenia rozporządzenia (UE) nr 526/2013 (akt o cyberbezpieczeństwie), http://data.europa.eu/eli/reg/2019/881/oj (dostęp: 23.03.2022).
[4] ENISA, Privacy and Data Protection by Design, 2015, https://www.enisa.europa.eu/publications/privacy-and-data-protection-by-design (dostęp: 16.03.2022).
[5] M. Hansen, M. Jensen, M. Rost, Protection Goals for Privacy Engineering, 2015 IEEE Security and Privacy Workshops, 2015.
[6] Opinia 05/2014 w sprawie technik anonimizacji, przyjęta w dniu 10 kwietnia 2014 r. przez Grupę Roboczą Art. 29, https://archiwum.giodo.gov.pl/pl/file/6338 (dostęp: 16.03.2022).
[7] C. Dwork, A. Roth, The Algorithmic Foundations of Differential Privacy, Foundations and Trends in Theoretical Computer Science, 2014.
[8] C. Clifton and T. Tassa, „On syntactic anonymity and differential privacy,” in IEEE 29th International Conference on Data Engineering Workshops (ICDEW), 2013.
[9] M.A. Will, R. Ko, A guide to homomorphic encryption, The Cloud Security Ecosystem, Syngress, 2015, s. 101127.
[10] P. Bogetoft, D.L. Christensen, I. Damgård i in., Secure Multiparty Computation Goes Live, Financial Cryptography and Data Security, 2009.
[11] D. Asonov, Private Information Retrieval – An Overview and Current Trends, 2011.
[12] R. Ostrovsky, W.E. Skeith, A Survey of Single-Database Private Information Retrieval: Techniques and Applications, PKC 2007: Public Key Cryptography, 2007.
[13] European Data Protection Board, Statement of the EDPB on the revision of the ePrivacy Regulation and its impact on the protection of individuals with regard to the privacy and confidentiality of their communications, 2018, https://edpb.europa.eu/our-work-tools/our-documents/other/statement-edpb-revision-eprivacy-regulation-and-its-impact_en (dostęp: 16.03.2022).